
前言
上篇文章中,我尝试爬取闲鱼商品数据。本次来尝试爬取1688商品。 1688的 PC 端页面是一个典型的“混合渲染”迷宫。 起初我尝试用 Playwright 的常规方法 page.evaluate() 去读取页面上的全局变量,结果撞了墙:明明在浏览器控制台能看到的 window.context,脚本读出来却是 null。排查后发现,这是因为 1688 采用了复杂的闭包初始化和页面注水(Hydration)机制,导致 JS 执行时机难以把控。(应该吧)
耗费时间去调试 JS 执行时机并不划算,于是我转向了**“逆向抓包 + 正则”**的方案。本文将详细记录如何绕过浏览器 JS 执行,直接从网络层和源码层抓出我们需要的所有数据。
一、抓包:数据到底藏在哪?
与闲鱼类似,1688 的数据源分为两块,我们需要分别击破: **动态数据(价格/库存)**走 API,**静态数据(属性/详情图)**埋在 HTML 源码里。
1. SKU 体系:mtop 协议监听
SKU 数据(比如:红色-L码-100件-单价5元)不在 HTML 里,而是页面加载后通过 mtop 接口异步拉取的。 打开 F12 Network 面板,刷新页面,搜索 queryofferskuselectormodel,你会找到这个核心包:
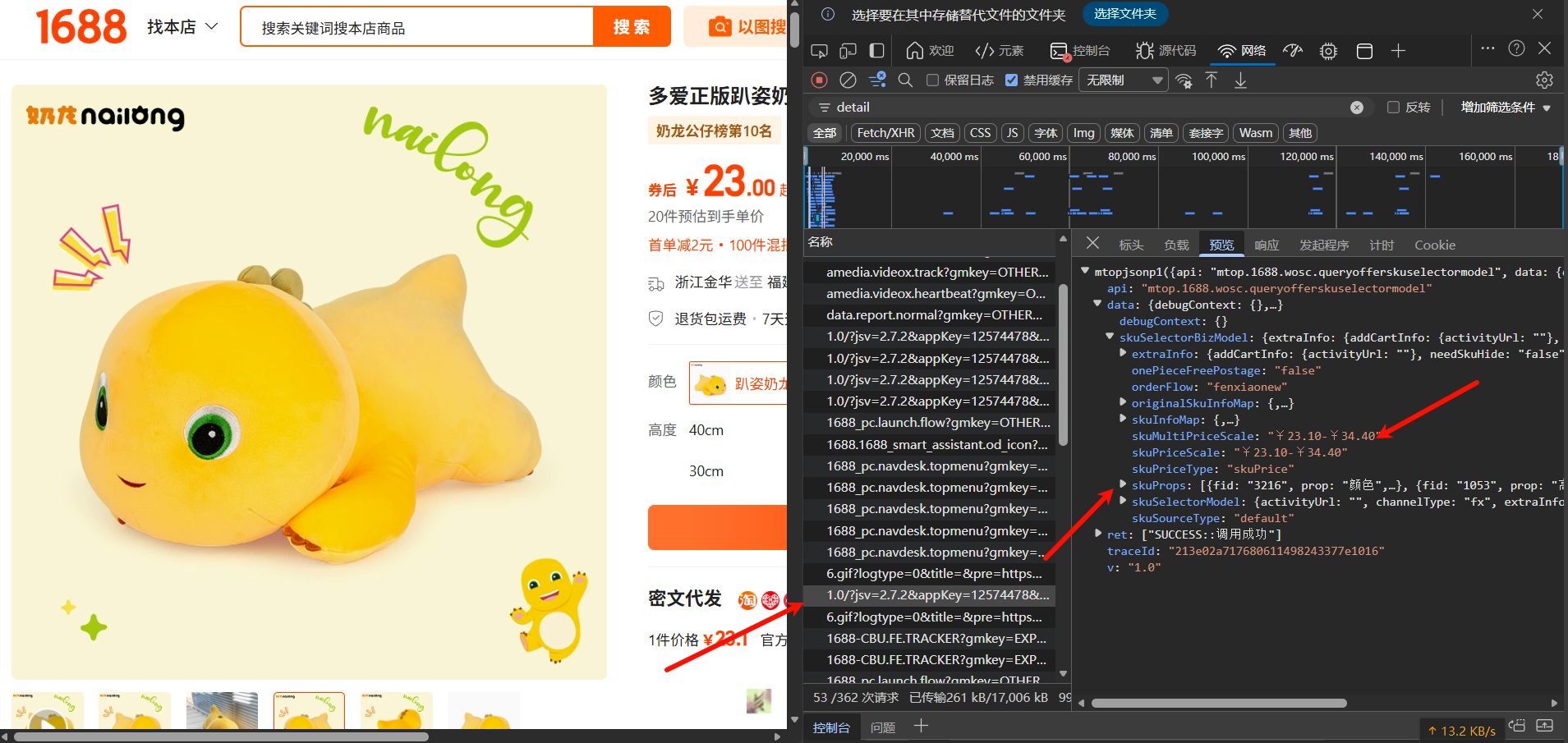
接口特征:mtop.1688.wosc.queryofferskuselectormodel
请求方式:GET (JSONP)
数据结构:
skuPropsList:定义了规格维度(颜色、尺寸)和对应的缩略图。skuMapOriginal:这是最关键的字典,Key 是规格组合(如颜色:红色;尺码:L),Value 包含真实成交价(discountPrice)和实时库存(canBookCount)。
实战结论:不需要去逆向复杂的 Sign 签名来伪造请求,直接用 Playwright 做个”中间人”,监听并拦截浏览器发出的合法请求即可,这点和闲鱼的方式一样。
2. 属性与详情:HTML 里的捉迷藏
商品的属性参数(如材质、品牌)和详情长图链接,藏在页面源码的一段硬编码脚本中:
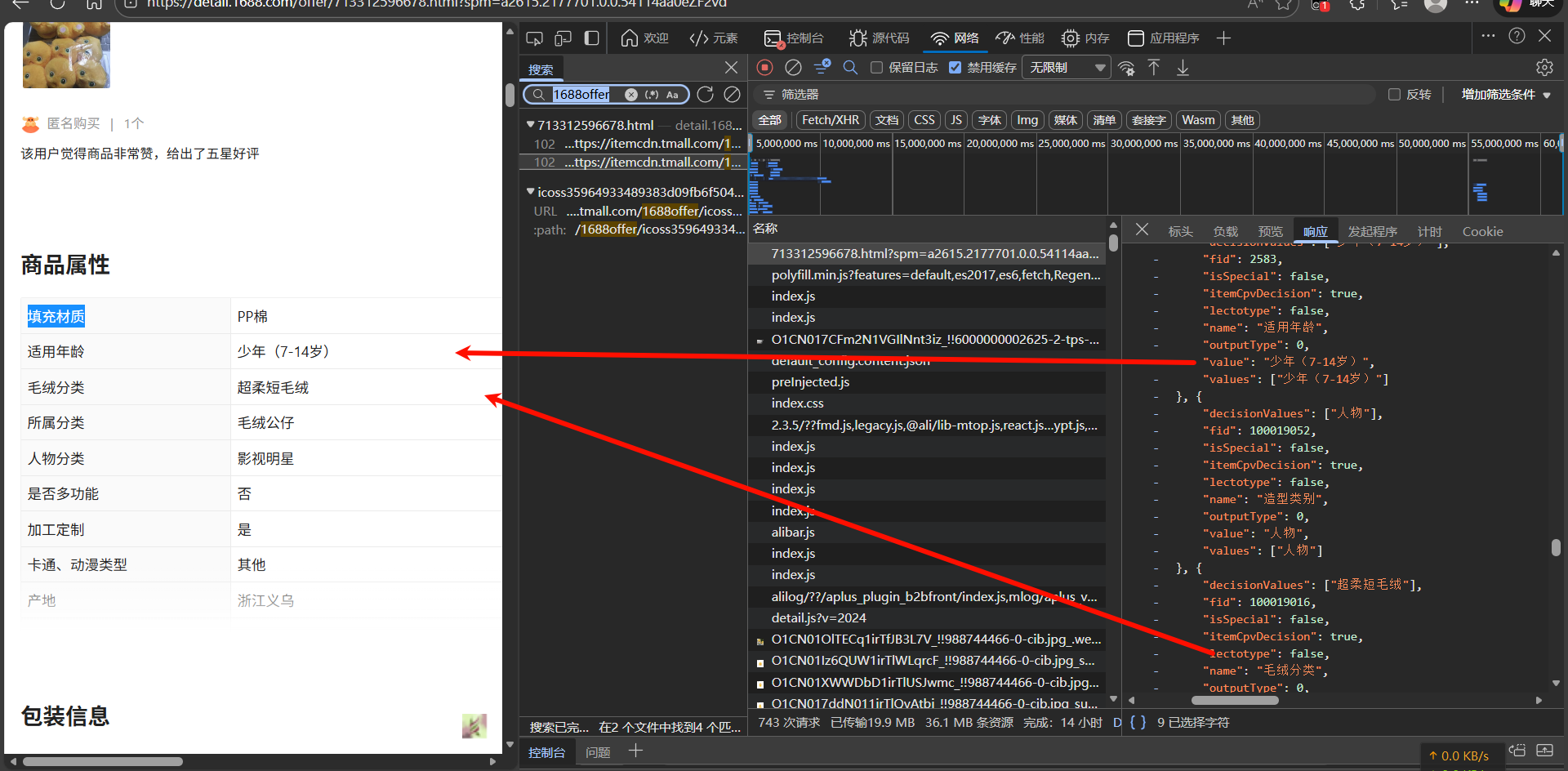
window.context = (function(b, d) { ... })(window.contextPath, { "result": { "data": { "offerDetail": { "featureAttributes": [...] // 想要的数据在这里 }, ..... "description": { "detailUrl": "..." // 详情图 API 地址 } } }});常规爬虫会尝试等待页面加载完成后,通过 JS 读取 window.context。但在实测中,由于闭包写法和执行顺序问题或者包内容过于复杂,也许是我技术不够(悲,Playwright 经常拿不到这个对象,只能通过 html 正则获取。
详情图在本html页面有两个地方,这里只介绍一个地方,另外一个地方在上图末尾处(好像是,大伙自己找找吧)
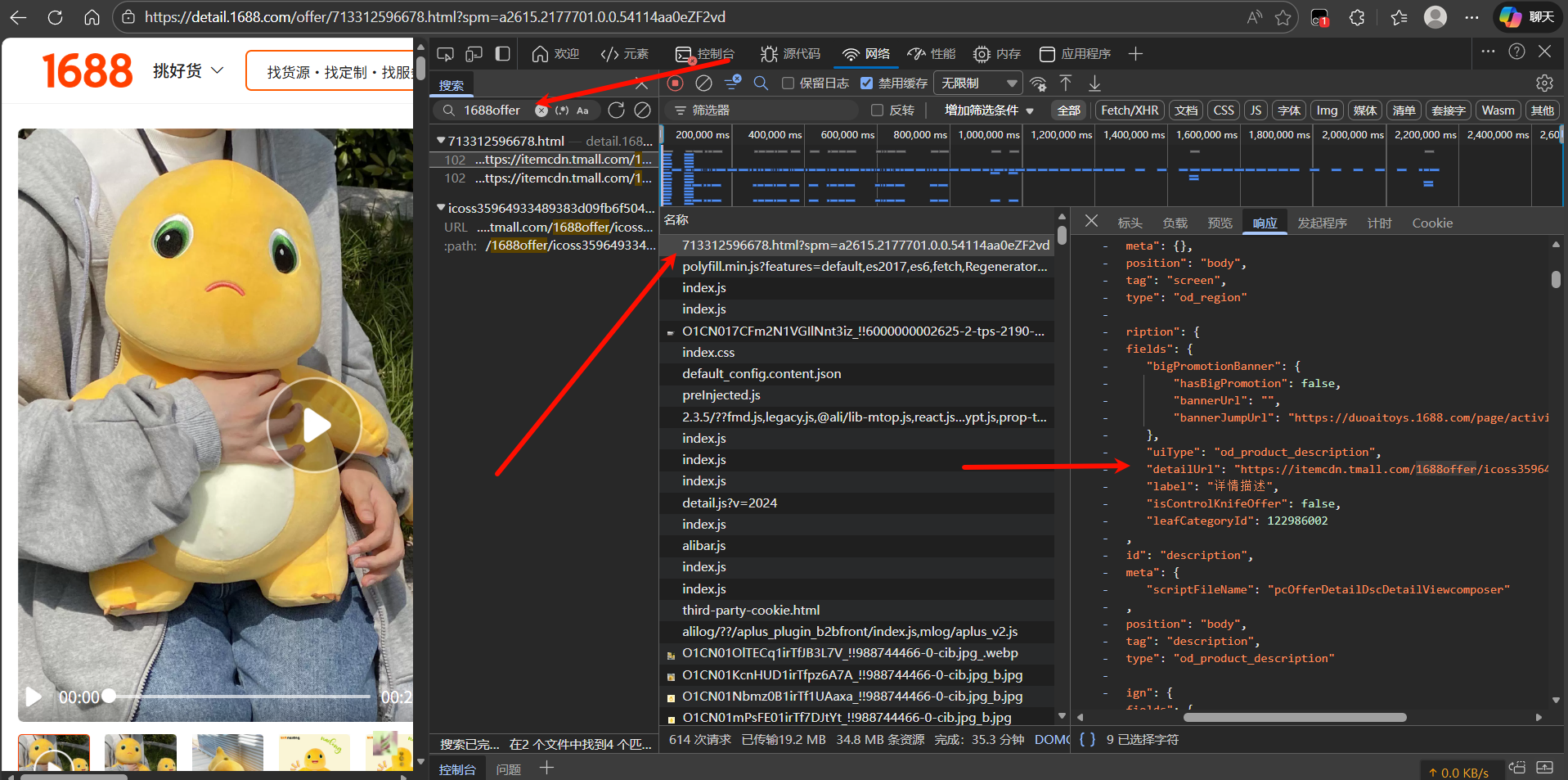
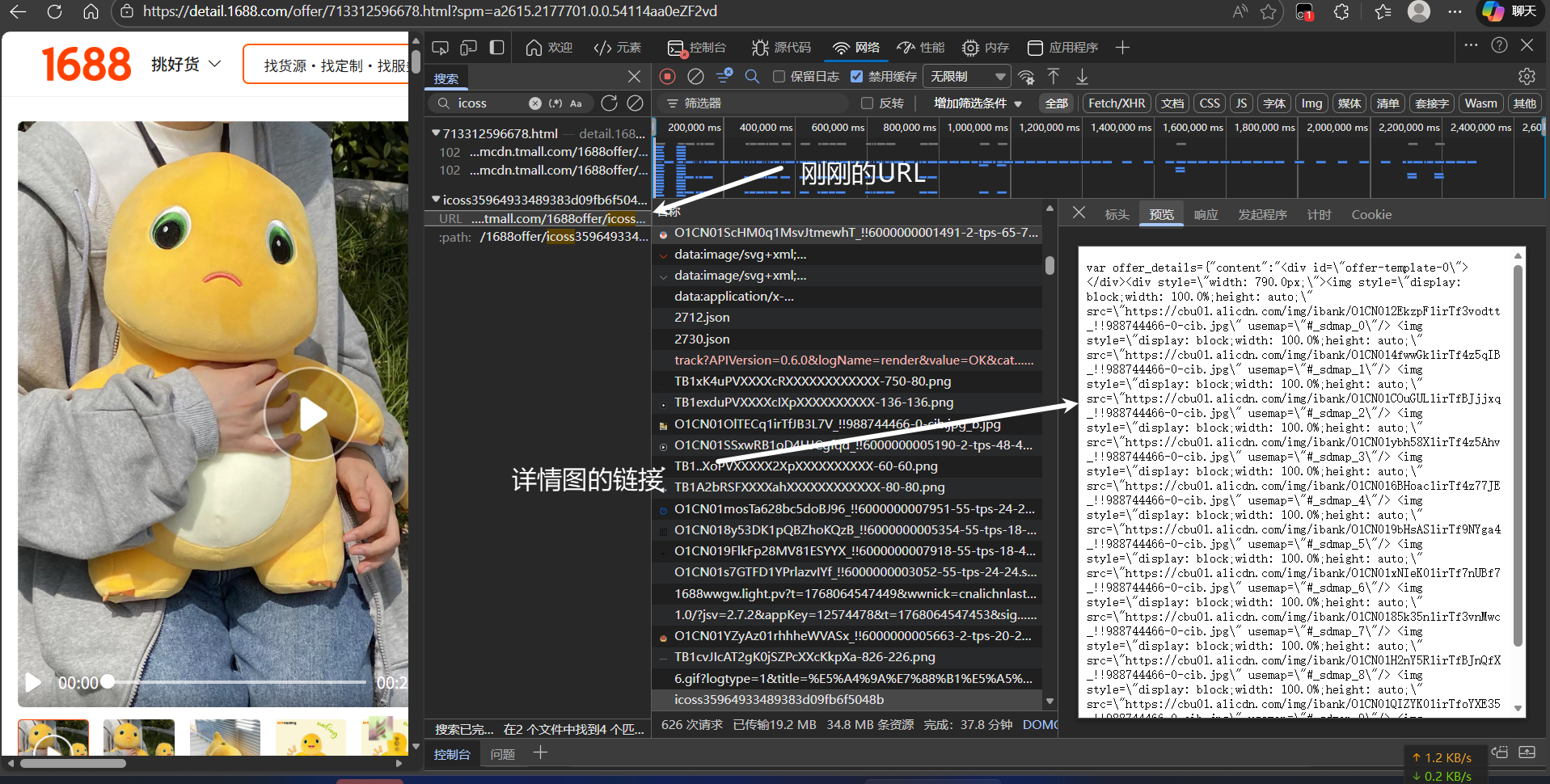
详情图API调用后给出的也不是常规 json,同样使用正则获取即可。注意要转换为标准 URL。
实战结论:只要它存在于 HTML 源码中,我们就可以用正则表达式把它提取出来。
二、避坑指南:四大”雷点”
在编写代码时,我遇到的几个问题,总结如下:
💥 雷点 1:JS 提取返回 Null
现象:data = await page.evaluate("() => window.context") 经常报错或返回空。
原因:页面 JS 执行环境复杂,变量未挂载或被混淆,或者无法准确定位位置。
解决:使用 page.content() 获取纯文本 HTML,直接上正则匹配。
💥 雷点 2:转义字符的干扰
现象:提取出的图片链接无法访问,比如 https:\/\/cbu01...。
原因:服务端返回的 JSON 数据经过了序列化转义。
解决:拿到字符串后,必须先做全局替换 .replace("\\", ""),还原成标准 URL。
💥 雷点 3:Cookie 必须固化
现象:脚本运行几次后被重定向到登录页。
原因:1688 对未登录查看价格有严格限制,而且未登录数据包名貌似会发生变化,导致抓不到数据。
解决:首次人工扫码登录后保存 auth.json,我这里是专门做了个脚本用来登录保存。之后脚本直接加载 Session,不要每次都重新登录。
怎么四个雷点又只有三个呢(
## 三、Python 关键代码解析
1. 正则提取(核心逻辑)
直接绕过浏览器 JS 解析,从 HTML 源码中提取属性。
def extract_attributes_directly(html_content): """ 直接正则匹配 featureAttributes 数组 """ # 查找 "featureAttributes": [...] 结构,无视 JS 执行状态 pattern = r'"featureAttributes"\s*:\s*(\[\{.*?\}\])' match = re.search(pattern, html_content, re.DOTALL)
attr_list = [] if match: try: # 拿到字符串直接转 JSON,干净利落 feature_attrs = json.loads(match.group(1)) for item in feature_attrs: name = item.get("name") val = item.get("value") if name and val: attr_list.append(f"{name}: {val}") except: pass return attr_list2. 流量监听器
不主动请求 API,直接拦截 SKU 数据包。
async def on_response(response): # 锁定 SKU 核心接口 if "queryofferskuselectormodel" in response.url and response.status == 200: try: text = await response.text() # 清洗 JSONP 的括号 wrapper:callback(...) if "(" in text and ")" in text: text = text[text.find("(")+1 : text.rfind(")")]
json_data = json.loads(text) # 解析 SKU 数据的逻辑... parsed = parse_sku_packet(json_data) if parsed: data_container["skus"] = parsed except: pass
# 注册监听page.on("response", on_response)3. 详情图旁路下载
拿到 detailUrl 后,由于详情图是放在阿里 CDN 中,无需鉴权,直接用 requests 下载图片即可。
# 1. 从源码正则提取 detailUrlmatch = re.search(r'"detailUrl"\s*:\s*"(https?://.*?)"', page_content)detail_url = match.group(1)
# 2. 旁路请求(不占用浏览器资源)resp = requests.get(detail_url, headers=headers)
# 3. 正则提取所有图片链接images = re.findall(r'(https?://[^"\'\\]+?\.(?:jpg|png|jpeg))', resp.text)# 放入后台线程池下载总结
通过 “Playwright 监听动态 API” + “正则解析静态 HTML” 的混合架构,解决了 1688 PC 端数据采集的痛点。
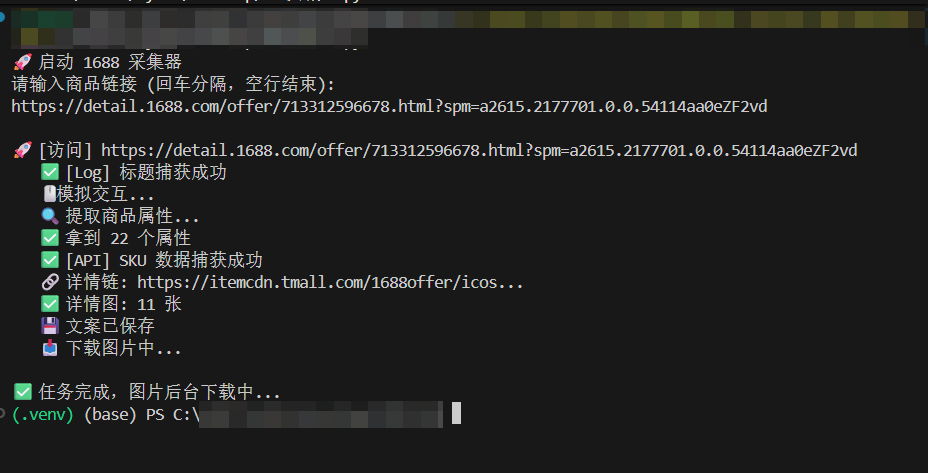
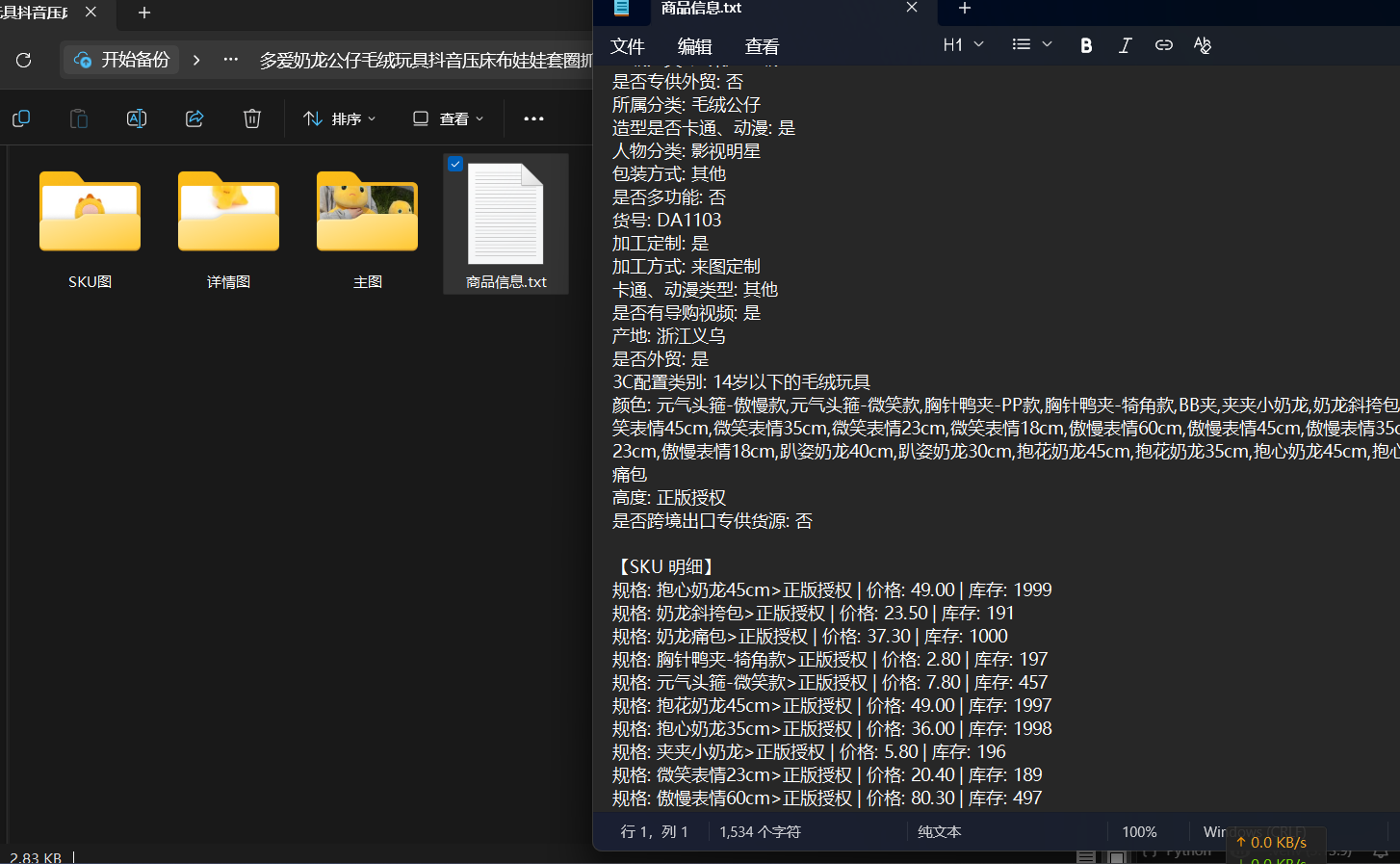
实战效果:
不用多说自己看图
IMPORTANT出于各种因素考虑,本文及其后续爬虫文章不会放出完整代码,有需要的小伙伴自行测试编写即可。
题外话
上个闲鱼的从项目起步到完成,只用了2个多小时(闲鱼大部分数据都是能明文找到位置),而1688环境更为复杂,从起步到完成花了快一天时间(还是有AI的情况下),属于是难度提升了不少。我也不是技术大牛,后续可能会尝试爬取淘宝,京东等,如果有其他实现方法欢迎邮箱联系交流学习。
法律声明爬虫技术仅用于学习交流,请勿用于非法商业用途,并严格遵守平台 Robots 协议。