
前言
继上一篇搞定 1688 之后,我将目光投向了跨境电商平台——亚马逊(Amazon)。
相比于 1688,亚马逊的反爬机制和页面复杂度提升了一个量级,对比下来闲鱼简直是新手村(哭。特别是它的 Twister 变体系统(即颜色、尺寸的联动逻辑)和混合加载机制,让传统的 DOM 解析几乎失效。
在经历了数次的试错,我构建了一套基于 Playwright + 堆栈式数据提取 + FFmpeg 并发 的稳定方案。本文分享我们在处理 SKU 映射、高清视频下载以及懒加载交互上的核心技术实现。
一、核心难点分析
在开发初期,我们主要面临三大挑战:
- 数据碎片化:亚马逊的 SKU 数据(图片、ASIN、属性)并不在一个统一的 JSON 里,而是分散在
jQuery.parseJSON、P.register以及动态 AJAX 请求中 - 代码压缩与混淆:页面源码经过高度压缩(Minified),一行代码可能长达几万字符。简单的正则表达式在匹配嵌套 JSON 时极其容易失效或溢出
- 视频流陷阱:直接抓取的视频链接往往是 m3u8 的 Master Playlist(仅几KB),包含的是分片索引而非视频本身,导致无法直接保存播放
二、架构设计
为了解决上述问题,我们采用了如下的模块化架构:
- 交互层 (Interaction):使用 Playwright 进行”拉锯式”滚动,触发所有懒加载组件
- 解析层 (Parser):放弃不可靠的正则全匹配,用字符堆栈提取核心 JSON 数据
- 下载层 (Downloader):调用系统级 FFmpeg 进程,实现 m3u8 自动合并与多进程并发
三、技术实现细节
1. 攻克 Twister:堆栈式 JSON 提取
亚马逊的商品数据通常被封装在 P.register('twister-js-init-dpx-data', function() { var dataToReturn = { ... } }) 这种闭包里。
这里我不再截图了(因为做的时候忘记截图了),直接搜索 CTRL+F 搜索吧。
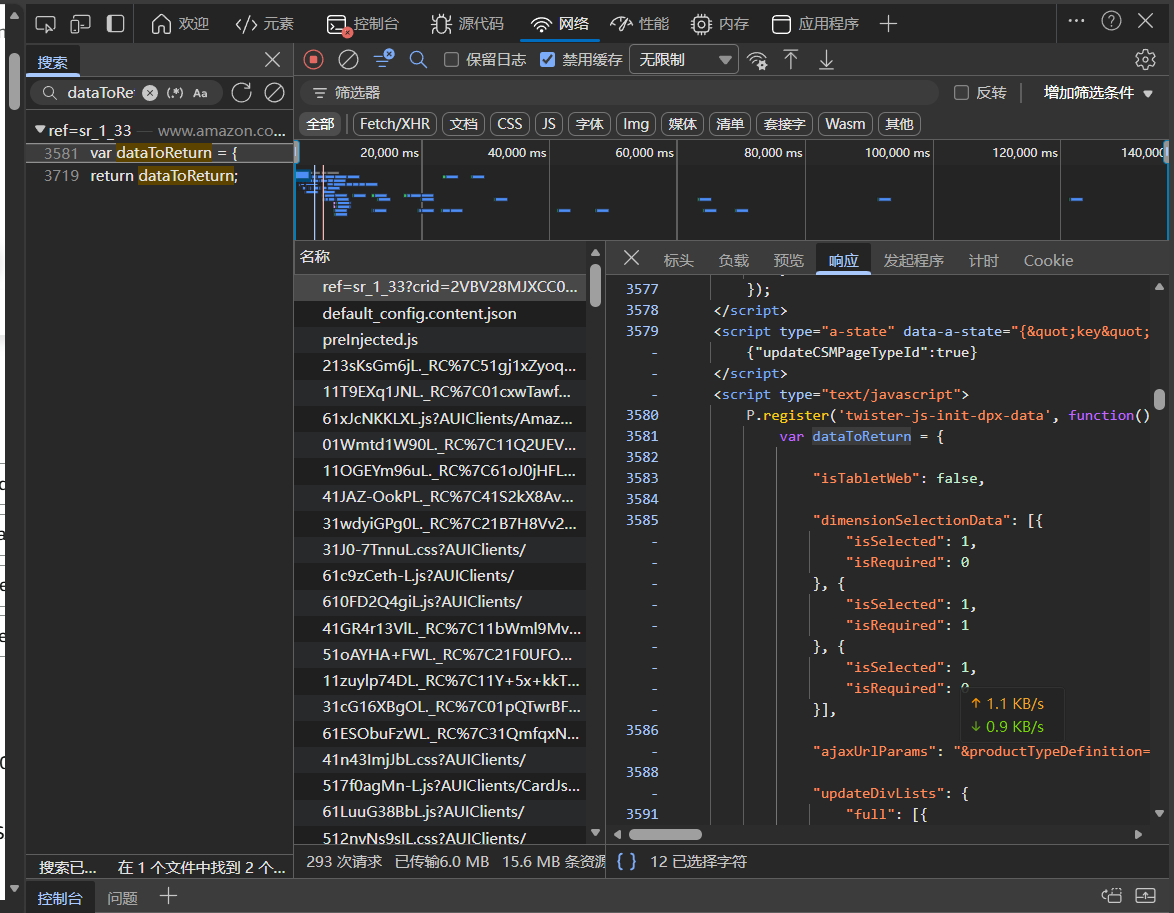
还是回去截了个图,基本上数据都在这个包里,包括颜色和大小(不过本文没有做大小爬取,因为本来要做 SKU 全量爬取的,后面失败了)。
起初我尝试用 re.search(r'var dataToReturn = ({.*?})', html),但由于 JSON 内部包含大量嵌套的大括号 {},正则的贪婪匹配经常抓错结束位置,导致 JSON 解析失败。特别是在源码被压缩成一行时,正则几乎不可用。
解决方案:字符堆栈分析法
既然正则搞不定嵌套,我们就模拟编译器的原理。从变量定义处开始,逐个字符读取,遇到 { 入栈(计数+1),遇到 } 出栈(计数-1)。当计数器归零时,我们就完美剥离出了一个完整的 JSON 对象。
def extract_json_by_stack(html_content): """ 核心算法:通过数大括号的方式提取核心数据 解决正则匹配不完整导致的 JSON 解析错误 """ # 1. 定位变量起点 start_marker = "var dataToReturn =" start_idx = html_content.find(start_marker) if start_idx == -1: return {}
# 2. 找到第一个左括号 cursor = html_content.find("{", start_idx) if cursor == -1: return {}
# 3. 堆栈计数 brace_count = 0 json_str = "" found_end = False
# 截取缓冲区,避免全页遍历 buffer = html_content[cursor : cursor + 500000]
for char in buffer: json_str += char if char == '{': brace_count += 1 elif char == '}': brace_count -= 1 # 闭合检测 if brace_count == 0: found_end = True break
if found_end: try: # 数据清洗与加载 return json.loads(json_str) except json.JSONDecodeError: pass # 容错处理 return {}通过这个方法,我们成功拿到了 colorImages(高清图映射)和 sortedDimValuesForAllDims(SKU 映射关系),无论亚马逊前端代码如何压缩,只要结构不变,数据就能取到。
2. 视频下载:FFmpeg 多进程并发
亚马逊的视频使用的是 HLS 协议(.m3u8)。如果你直接用 requests.get 下载,只会得到一个包含分片地址的文本文件,只有几 KB,根本播放不了。
解决方案:
不要尝试用 Python 去解析 m3u8 然后一个个下 ts 切片再合并,那样效率太低且容易出错。最稳健的方法是直接调用系统安装的 ffmpeg。
为了提升速度,我们引入了 asyncio.Semaphore 来控制并发数,同时开启 5 个 FFmpeg 子进程进行下载。
async def download_video_ffmpeg(url, path, semaphore): # 检查文件是否已存在且有效 if os.path.exists(path) and os.path.getsize(path) > 10240: return
async with semaphore: print(f"🎬 [FFmpeg启动] 正在下载: {os.path.basename(path)}")
# 构造命令:-copy 模式不转码,速度极快 # -bsf:a aac_adtstoasc 用于修复音频流格式 cmd = [ "ffmpeg", "-y", "-v", "error", "-protocol_whitelist", "file,http,https,tcp,tls,crypto", "-i", url, "-c", "copy", "-bsf:a", "aac_adtstoasc", path ]
try: # 异步调用子进程,不阻塞主线程 process = await asyncio.create_subprocess_exec(*cmd) await process.wait() except Exception as e: print(f"❌ 下载失败: {e}")3. 强制交互:触发“懒加载”
亚马逊页面有大量的 Lazy Load (懒加载)机制。关联视频(Related Videos)和买家秀通常在页面底部,如果不滚动到可视区域,浏览器根本不会发送请求。
简单的 page.keyboard.press("PageDown") 往往不够,因为滑得太快服务器反应不过来。我们实现了一种**“拉锯式滚动”**策略:
# 获取页面总高度page_height = await page.evaluate("document.body.scrollHeight")scroll_step = 200 # 每次滚动200像素total_steps = max(1, int(page_height / scroll_step)) # 至少1步scroll_duration = 5 # 总共5秒delay_per_step = scroll_duration / total_steps # 每步延迟时间
# 从上到下慢慢滚动current_scroll = 0while current_scroll < page_height: await page.evaluate(f"window.scrollTo(0, {current_scroll})") current_scroll += scroll_step await asyncio.sleep(delay_per_step)
# 确保滚动到底部await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")await asyncio.sleep(1)
# 扫描视频容器(其实这一段代码没啥用,根本定位不到,但是我还是保留了,小伙伴们使用时可以删掉这个)print(" -> 扫描视频板块...")try: video_loc = page.locator("#vse-related-videos, .vse-related-videos-container, #aplus").first if await video_loc.count() > 0: await video_loc.scroll_into_view_if_needed() await asyncio.sleep(2)except: pass4. 启动时触发机器人验证
启动都触发到机器人验证,但是是有时候会有,触发频率玄学。
解决方案:无解,即便我完美复刻浏览器标头,纯净IP,都无法避免这个问题。但是点击一次后,后面几次大概率不会弹出。做一个等待函数等待用户完成验证即可。
四、成果展示
经过上述优化,爬虫运行稳定。它会自动创建一个以商品标题命名的文件夹,并生成详细的txt。
文件夹结构:
Amazon_Downloads/└── Carhartt Mens Loose Fit T-Shirt/ ├── Images/ │ ├── Black_1.jpg │ ├── Black_2.jpg │ ├── Navy_1.jpg │ └── ... ├── Videos/ │ ├── Main_Video.mp4 │ └── Review_Video_1.mp4 └── info.txt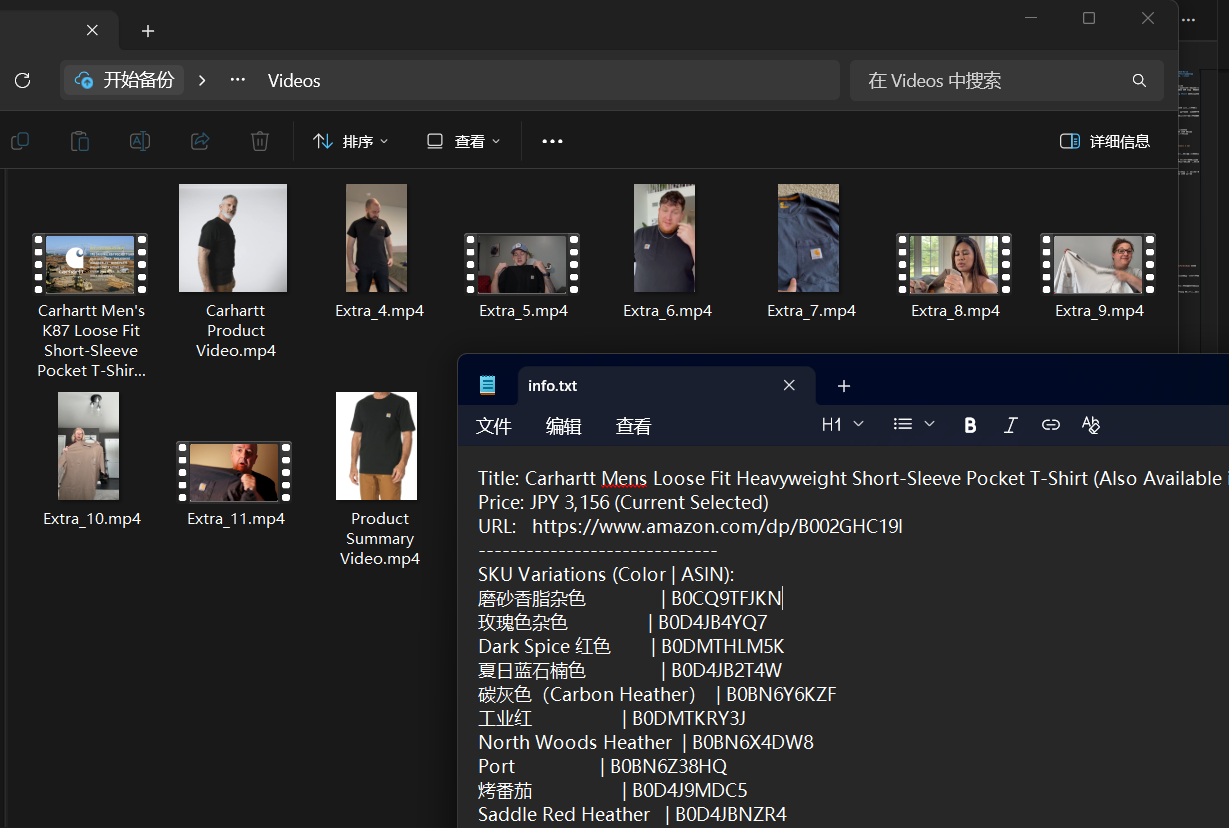
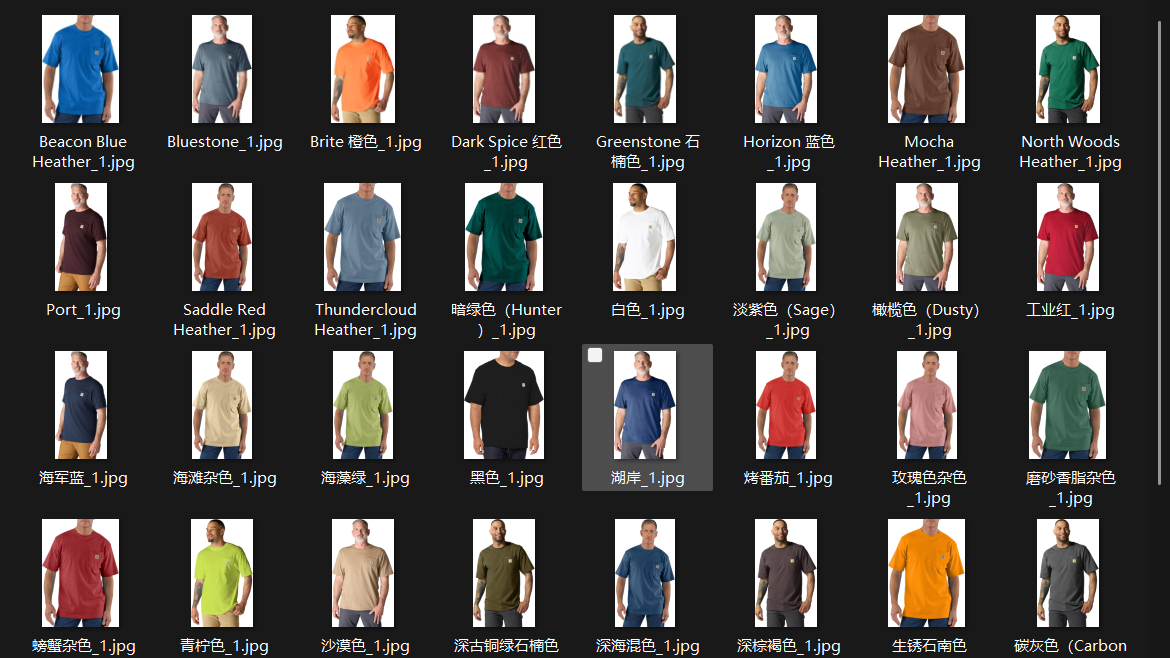
info 内容:包含了每个 SKU 的颜色、ASIN,以及商品链接标题和默认价格。
总结
开发亚马逊爬虫的过程,实际上是一个与**“前端工程化”**博弈的过程。
- 页面源码不再是简单的 HTML,而是被 Webpack 等工具打包压缩后的 JS 闭包,这逼迫我们放弃正则,转向堆栈分析
- 媒体资源不再是直链,而是流媒体协议(HLS),这要求我们引入 FFmpeg 进行流处理
- 数据不再是静态渲染,而是各种 Hydration 和 Lazy Load,这要求我们编写更拟人的交互脚本
其实本来想做每个 SKU 的 SIZE 和价格都标出来,即颜色 + ASIN + 可供选择的 SIZE + 价格。奈何亚马逊的页面复杂到我无法解析,基本上每点一个颜色,都会回传一大批数据,我无法使用抓包分析,或许直接抓 DOM 可以,但是太麻烦了,我也不想做(被这个恶心到了,或许某天闲着没事会来尝试一下)。本脚本开发时间耗时接近 8 个小时。
IMPORTANT出于各种因素考虑,本文及其后续爬虫文章不会放出完整代码,有需要的小伙伴自行测试编写即可。
法律声明本文代码片段仅供技术研究与学习使用,请勿用于大规模数据抓取或商业用途,遵守目标网站的 Robots 协议。