
前言
最近在做电商数据分析,目标是抓取闲鱼某个特定卖家的所有在售商品(包括高清图、文案、价格)。起初尝试用 requests 直接请求接口,结果撞上了阿里系著名的 x-sign 签名验证和 WUA 设备指纹墙。耗费大量时间去逆向 JS 并不划算,于是我转向了 Playwright + 流量监听 的方案。
本文将详细记录如何从复杂的网络请求中定位核心数据包,以及在编写代码时遇到的几个雷点。
一、硬核抓包:数据到底藏在哪?
闲鱼 Web 端的数据加载逻辑非常典型:HTML 骨架 + API 异步加载数据。这意味着直接爬 HTML 源码是拿不到数据的,我们必须去分析 Network 网络请求。
1. 列表页抓包分析
打开卖家主页,按 F12 打开开发者工具,切换到 Network -> Fetch/XHR。当我们向下滑动加载更多商品时,会发现一个关键请求:
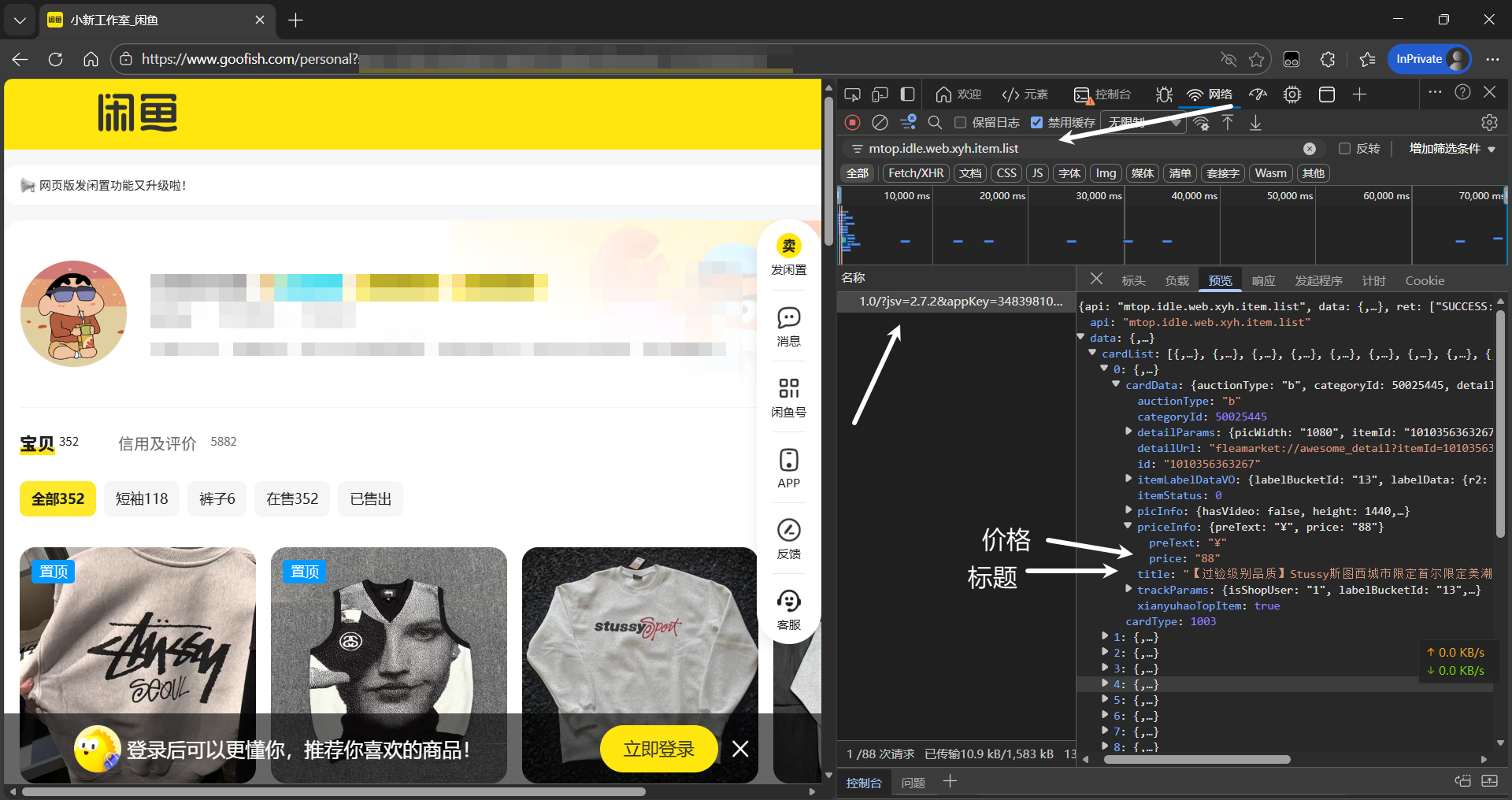
接口名称:mtop.idle.web.xyh.item.list
请求方式:GET/POST
关键载荷 (Payload):
{ "userId": "2217xxxxxxxxx", // 目标卖家ID "pageNumber": 2, // 页码 "scene": "seller_home"}数据结构:响应数据通常在 data.items 或 data.cardList 中。这里包含了商品的 itemId(商品ID)、title(标题)和 soldPrice(价格)。拿到 itemId 是第一步,因为详细的文案和高清大图,必须进详情页才能拿到。
2. 详情页的”俄罗斯套娃”
当你点击进入商品详情页(https://www.goofish.com/item?id=...),会发现找不到标准的 “description” 字段。
经过逐个排查 mtop 开头的请求,我锁定了核心包:
接口名称:mtop.taobao.idle.pc.detail
数据陷阱:你以为数据在 data.desc 里?错。闲鱼为了复用移动端逻辑,把核心数据压缩成了一个 JSON 字符串,塞进了另一个字段里。
请看这个**“套娃”结构**:
{ "data": { "itemDO": { "shareData": { // 注意:这个字段的值是一个 String,不是 Object! "shareInfoJsonString": "{\"contentParams\":{\"mainParams\":{\"content\":\"这里才是真正的文案...\",\"images\":[...]}}}" } } }}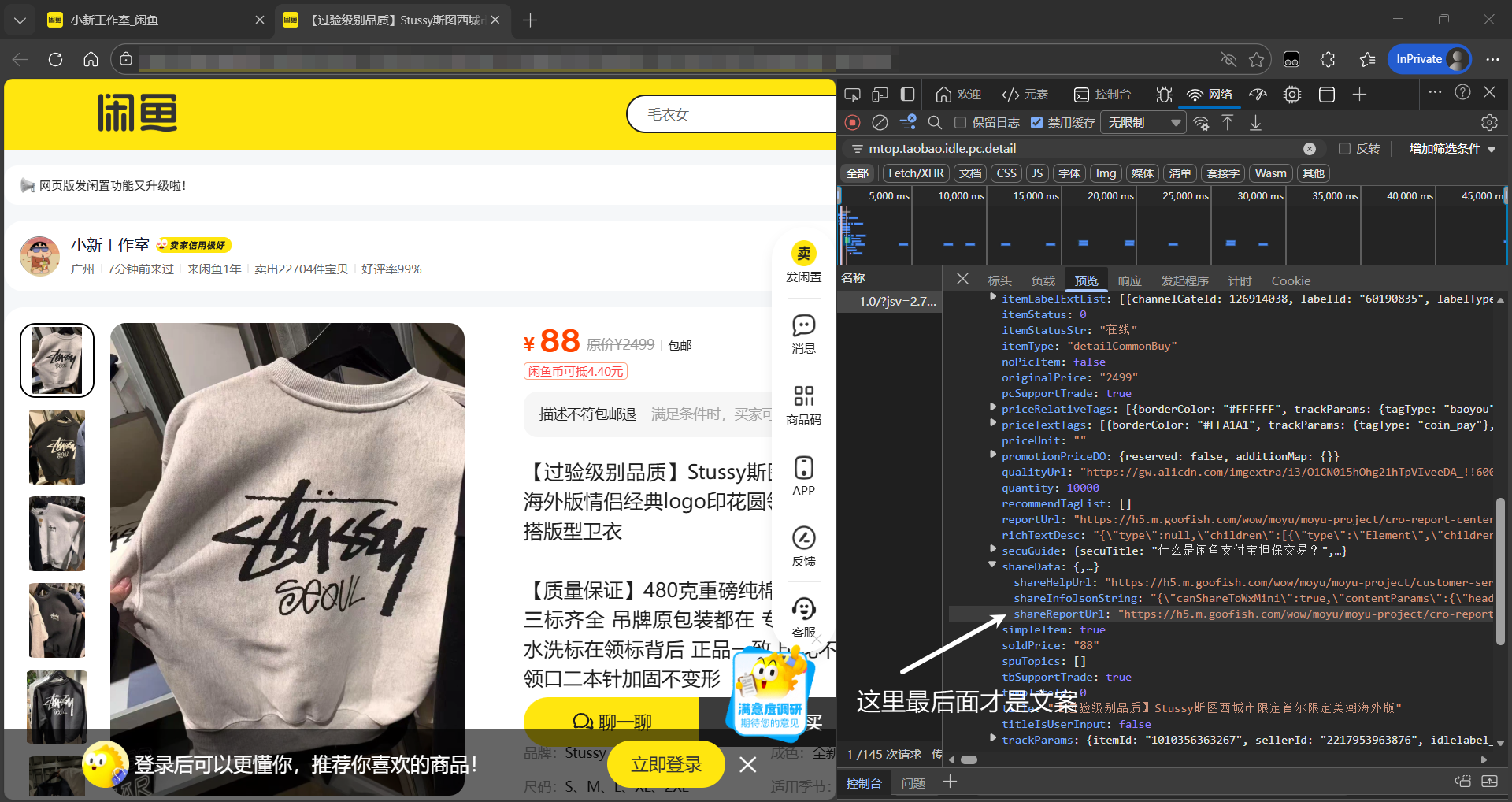
实战结论:我们在写代码时,必须进行二次解析:先解析外层 JSON,提取出 shareInfoJsonString,再对这个字符串进行 json.loads,才能拿到高清原图列表(images)和详细描述(content)。
二、避坑指南:四大”雷点”
在开发过程中,我踩了无数坑,总结如下:
💥 雷点 1:无头模式的”隐形墙”
现象:代码设置 headless=True(不显示浏览器)运行时,死活抓不到数据,扫描到的商品数为 0。
原因:阿里风控能够检测无头浏览器(Headless Chrome)的特征。
解决:必须强制开启浏览器界面 headless=False。如果不想看界面,可以手动最小化窗口。
💥 雷点 2:风控登录请求
现象:有时候爬着爬着就会弹出登录请求,导致程序中断
原因:可能是爬取触发风控,要求用户登录
解决:在脚本启动时增加检测逻辑,如果发现页面跳转到登录页,暂停脚本,人工扫码登录,获取到 Cookie 后再继续。但是如果触发滑块验证直接无解,请适当调低频率。
💥 雷点 3:图片加载拖慢速度
现象:抓取 300 个商品需要半小时,大部分时间花在加载图片上。
原因:我们只需要 JSON 数据,但浏览器默认会下载网页上的所有图片,浪费带宽和时间。
解决:利用 Playwright 的路由拦截功能,屏蔽所有图片和字体文件的请求。
四个雷点只有三个不是很正常(大嘘
三、Python 关键代码解析
1. 资源拦截
凡是图片、字体,统统直接拒绝,不要下载。
# 拦截无用资源,极大提升页面加载速度await page.route( "**/*.{png,jpg,jpeg,gif,webp,svg,ttf,woff,woff2}", lambda route: route.abort())2. 被动流量监听(核心逻辑)
不主动发起 requests.get,而是像监听器一样,守在浏览器旁边,一旦发现目标数据包经过,就把它截获下来。
async def handle_detail(response): # 只拦截详情接口,且状态码必须是 200 if "mtop.taobao.idle.pc.detail" in response.url and response.status == 200: try: json_data = await response.json() # 调用解析函数处理数据 parsed_data = parse_detail_packet(json_data) if parsed_data: # 存入结果容器 result_container["data"] = parsed_data except: pass
# 注册监听器page.on("response", handle_detail)3. “套娃”数据解析
这是对应上面抓包分析的代码实现,专门处理 shareInfoJsonString。
def parse_detail_packet(data): # 1. 安全校验:过滤非目标卖家的商品(防止抓到推荐商品) current_seller_id = data.get("sellerDO", {}).get("sellerId") if current_seller_id != TARGET_USER_ID: return None
# 2. 定位套娃字符串 item_do = data.get("itemDO", {}) share_json_str = item_do.get("shareData", {}).get("shareInfoJsonString", "")
desc_text = "" images = []
# 3. 二次解析 if share_json_str: inner_data = json.loads(share_json_str) # 关键一步 main_params = inner_data.get("contentParams", {}).get("mainParams", {})
# 提取真正的文案 desc_text = main_params.get("content", "") # 提取高清图列表 images = [img['image'] for img in main_params.get("images", []) if 'image' in img]
return { "title": item_do.get("title"), "desc": desc_text, "images": images }4. 异步并发控制
为了既快又不被封 IP,我们使用 asyncio.Semaphore 来限制同时打开的浏览器标签页数量(推荐 3 个)。
# 限制最大并发数为 3semaphore = asyncio.Semaphore(3)
async def worker(context, pid): async with semaphore: # 只有拿到信号量才能执行 page = await context.new_page() try: await page.goto(f"https://www.goofish.com/item?id={pid}") # ... 等待数据包捕获 ... finally: await page.close() # 随机休息 1-2 秒,模拟真人操作频率 await asyncio.sleep(random.uniform(1, 2))总结
通过 Playwright 的 “浏览器自动化 + 流量监听” 模式,我们成功绕过了复杂的签名验证。
实战效果:
- 速度:3 线程并发,抓取 300 个商品详情 + 下载 2000 多张图片,耗时约 15 分钟
- 稳定性:配合扫码登录和断点续传机制,可以稳定同步店铺数据
还可以配上 Python 正则分类,实现商品种类分类:
CATEGORIES = { "卫衣": ["卫衣", "帽衫", "HOODIE", "套头", "连帽"], "外套": ["外套", "夹克", "JACKET", "棉服", "羽绒服", "棒球服", "开衫", "皮衣", "底特律", "教练夹克", "飞行员", "帆布", "工装"], "短袖": ["短袖", "T恤", "TEE", "半袖", "短䄂"], "长袖": ["长袖"], "衬衫": ["衬衫", "SHIRT"], "裤子": ["裤子", "牛仔裤", "长裤", "短裤", "牛仔", "微喇"], "毛衣": ["毛衣", "针织", "马海毛", "海马毛", "圆领毛衣"],}
def get_category_from_text(text): """根据文本内容识别类别""" text = text.upper() for category, keywords in CATEGORIES.items(): for keyword in keywords: if keyword.upper() in text: return category return "其他"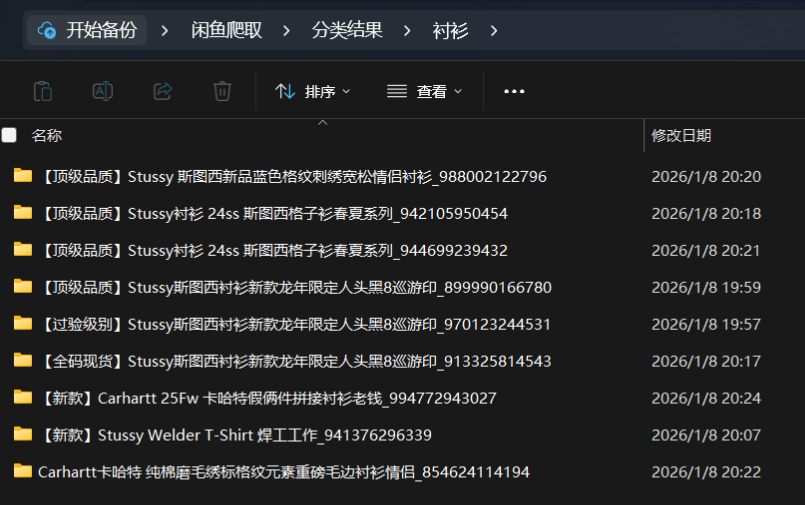
附上完整代码
import asynciofrom playwright.async_api import async_playwrightimport jsonimport timeimport osimport requestsimport reimport randomimport shutilfrom concurrent.futures import ThreadPoolExecutor
# --- ⚙️ 配置 ---BASE_DIR = "闲鱼店铺爬取"TARGET_USER_ID = "xxxxxxxxx" # 填写要爬取的商家id,就是URL后面那段数字HEADLESS = False # 必须显示浏览器CONCURRENCY = 3 # 同时打开的网页数量 (建议 2-3,太快会被封IP)WORKER_DELAY = (1, 2) # 单个窗口抓完后的休息时间 (秒)
# 图片下载专用线程池img_executor = ThreadPoolExecutor(max_workers=10)
def sanitize_filename(name): name = re.sub(r'[\\/:*?"<>|]', '', name).replace('\n', '') return name[:50].strip()
def download_image_sync(url, save_path): """(同步) 图片下载任务,丢给线程池跑""" try: if os.path.exists(save_path): return if url.startswith("http:"): url = url.replace("http:", "https:") if ".jpg_" in url or ".png_" in url or ".heic_" in url: url = url.split("_")[0]
headers = {"User-Agent": "Mozilla/5.0"} resp = requests.get(url, headers=headers, timeout=15) if resp.status_code == 200: with open(save_path, 'wb') as f: f.write(resp.content) except: pass
def parse_detail_packet(data): """解析详情包 (逻辑不变)""" try: # 卖家校验 seller_obj = data.get("sellerDO", {}) or data.get("seller", {}) current_seller_id = str(seller_obj.get("sellerId", "")) or str(seller_obj.get("userId", "")) if current_seller_id and current_seller_id != TARGET_USER_ID: return None # 过滤推荐
item_do = data.get("itemDO", {}) share_data = item_do.get("shareData", {}) share_json_str = share_data.get("shareInfoJsonString", "")
desc_text = "" images = []
if share_json_str: inner_data = json.loads(share_json_str) main_params = inner_data.get("contentParams", {}).get("mainParams", {}) desc_text = main_params.get("content", "") img_list = main_params.get("images", []) for img_obj in img_list: if "image" in img_obj: images.append(img_obj["image"])
if not desc_text: desc_text = item_do.get("desc", "无描述") if not images: for img in item_do.get("imageInfos", []): if "url" in img: images.append(img["url"])
price = item_do.get("soldPrice", "0") if price == "0": price = item_do.get("priceInfo", {}).get("price", "0")
return { "title": item_do.get("title", ""), "price": price, "desc": desc_text, "images": images, "itemId": item_do.get("itemId", "") } except: return None
async def scan_online_ids(context): """【第一步】异步全量扫描""" page = await context.new_page() online_ids = set()
print(f"📡 正在扫描卖家主页...") await page.goto(f"https://www.goofish.com/personal?userId={TARGET_USER_ID}")
# 登录检测 await asyncio.sleep(3) if "login" in page.url: print("\n🔴🔴🔴 检测到未登录!请手动扫码!🔴🔴🔴") while "login" in page.url: await asyncio.sleep(1) print("✅ 登录成功,继续扫描...")
async def handle_list(response): if "item.list" in response.url and response.status == 200: try: resp = await response.json() data = resp.get("data", {}) items = data.get("cardList") or data.get("items") or [] for item in items: pid = item.get("cardData", {}).get("detailParams", {}).get("itemId") if not pid: pid = item.get("data", {}).get("itemId") if pid: online_ids.add(str(pid)) print(f" 🔍 扫描中... 当前总数: {len(online_ids)}", end="\r") except: pass
page.on("response", handle_list)
# 快速翻页 print("\n📜 正在向下滚动...") no_change = 0 last_len = 0
while True: await page.keyboard.press("End") await asyncio.sleep(1.5) # 缩短翻页间隔
curr_len = len(online_ids) if curr_len == last_len: no_change += 1 print(f" ⚠️ 到底了? ({no_change}/6) 当前: {curr_len} ", end="\r") if no_change >= 6: break else: no_change = 0 last_len = curr_len
await page.close() return online_ids
async def worker(context, pid, semaphore): """【第三步】并发工作单元""" async with semaphore: # 限制并发数,防止开太多浏览器卡死 page = await context.new_page() # 屏蔽图片,极大提升速度 await page.route("**/*.{png,jpg,jpeg,gif,webp,svg}", lambda route: route.abort())
result_container = {"data": None}
# 定义监听器 async def handle_detail(response): if "mtop.taobao.idle.pc.detail" in response.url and response.status == 200: try: json_data = await response.json() parsed = parse_detail_packet(json_data) if parsed: result_container["data"] = parsed except: pass
page.on("response", handle_detail)
try: # print(f"🚀 [抓取中] ID: {pid}") # 嫌吵可以注释 await page.goto(f"https://www.goofish.com/item?id={pid}")
# 等待数据包,最多等 6 秒 start_t = time.time() while result_container["data"] is None and time.time() - start_t < 6: await asyncio.sleep(0.2)
item_info = result_container["data"]
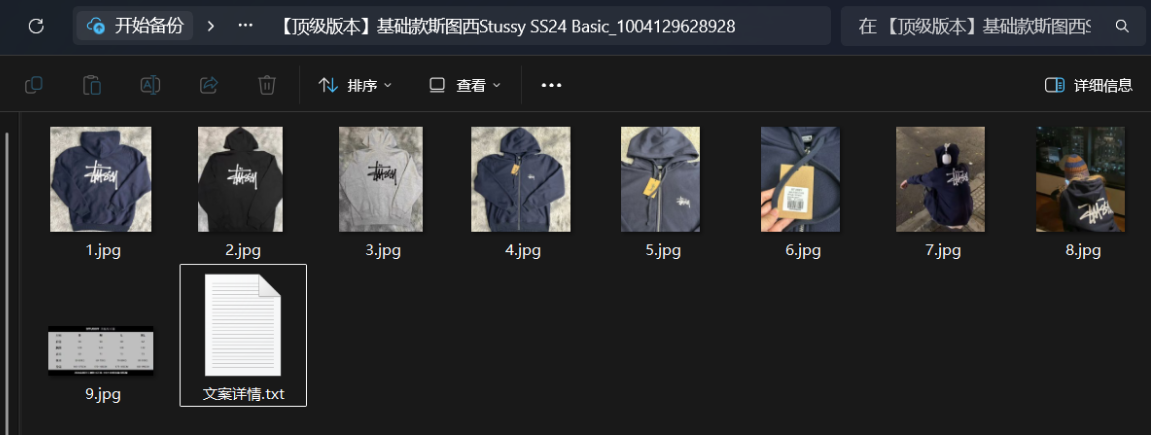
if item_info: # 1. 保存文案 title = item_info["title"] safe_title = sanitize_filename(title) folder_name = f"{safe_title}_{pid}" item_dir = os.path.join(BASE_DIR, folder_name) os.makedirs(item_dir, exist_ok=True)
with open(os.path.join(item_dir, "文案.txt"), "w", encoding="utf-8") as f: f.write(f"【标题】:{title}\n【价格】:{item_info['price']}\n【链接】:https://www.goofish.com/item?id={pid}\n\n【描述】:\n{item_info['desc']}")
print(f" ✅ [下载] {safe_title[:10]}... | 投递 {len(item_info['images'])} 张图")
# 2. 图片丢进后台线程池 for idx, url in enumerate(item_info["images"]): save_path = os.path.join(item_dir, f"{idx+1}.jpg") img_executor.submit(download_image_sync, url, save_path) else: print(f" ⚠️ [跳过] 抓取失败或非目标商品: {pid}")
except Exception as e: print(f" ❌ [异常] ID {pid}: {e}") finally: await page.close() # 极速版:只休息 1-2 秒 await asyncio.sleep(random.uniform(*WORKER_DELAY))
async def main(): if not os.path.exists(BASE_DIR): os.makedirs(BASE_DIR)
async with async_playwright() as p: print(f"🚀 启动浏览器 (并发数: {CONCURRENCY})...") browser = await p.chromium.launch(headless=HEADLESS) context = await browser.new_context()
# 1. 全量扫描在线 ID online_ids = await scan_online_ids(context)
# 安全阀 if len(online_ids) < 10: print("\n\n❌ 扫描到的商品太少,可能是登录失效,程序终止以防误删。") await browser.close() return
# 2. 本地对比 local_ids = set() local_map = {} # ID -> Path for folder in os.listdir(BASE_DIR): if "_" in folder: pid = folder.split("_")[-1] local_ids.add(pid) local_map[pid] = os.path.join(BASE_DIR, folder)
to_download = list(online_ids - local_ids) to_delete = local_ids - online_ids
print(f"\n📊 报告: 在线 {len(online_ids)} | 本地 {len(local_ids)} | 新增 {len(to_download)} | 删除 {len(to_delete)}")
# 3. 执行删除 if to_delete: print(f"🧹 清理 {len(to_delete)} 个下架商品...") for pid in to_delete: try: shutil.rmtree(local_map[pid]) print(f" ❌ 删除: {pid}") except: pass
# 4. 执行并发下载 if to_download: print(f"\n⚡ 启动并发下载引擎 (队列: {len(to_download)})...") semaphore = asyncio.Semaphore(CONCURRENCY) # 控制同时打开几个网页 tasks = [] for pid in to_download: task = asyncio.create_task(worker(context, pid, semaphore)) tasks.append(task)
# 等待所有任务完成 await asyncio.gather(*tasks) else: print("✨ 没有新商品需要下载。")
print("\n🎉 同步完成!等待图片下载收尾...") img_executor.shutdown(wait=True) print("✅ 退出。") await browser.close()
if __name__ == "__main__": asyncio.run(main())法律声明爬虫技术仅用于学习交流,请勿用于非法商业用途,并严格遵守平台 Robots 协议。